03 Feb 2020
“Scratch Notes” (?)
First, what is going on here: Some people do
weeknotes —
regular logs of work and things of interest. I like those! But I don’t find
myself personally motivated by a time-based cadence. I tend to hit some critical
mass of stuff in my head that I feel some need to get down.
Hence: scratch notes. I’m considering this a low-pressure vehicle for writing in
a somewhat longer form than something like Twitter, but impressionistic, and
decidedly unpolished. We’ll see! Maybe this will be the first and last one,
but doing has always brought the most learning for me anyway.
What I’ve been up to
After 6 years (!), last February I left Code for America. Since then I’ve been
rebalancing my life a bit: biking, riding trains, visiting family, taking ample
ferries.
Over the past 6 months I’ve also been doing some consulting and
contracting, mostly with people/orgs/companies I know.
In November, I also joined Public Digital’s Affiliates
Network, which means I’m doing the occasional consulting engagement alongside people whose work founding the UK Government Digital Service I’ve long held high.
I’ve also been spelunking various problem areas I find interesting,
building some experimental things, and generally looking for a next big lever
on problems I care about. (NB: I’m not looking for a full-time gig right now, but may be
doing that in the near future.)
Public Interest SEO
I’ve become very interested in search quality in public interest domains
recently. In part this has been catalyzed by some analogous work I stumbled upon in the legal tech space
(see below), but really it’s in part because it has the contours of a problem I
like: hidden in plain site, fairly technical/measurable, high leverage yet seemingly underpriced (seemingly not a lot
of ongoing work in the area.)
For example, if I search on Google for “food stamps” (something I happen to know
a lot/too much about) in San Francisco, we get this neat little “People Also
Ask” box that answers a question I probably have: What is the maximum income to
qualify for food stamps?
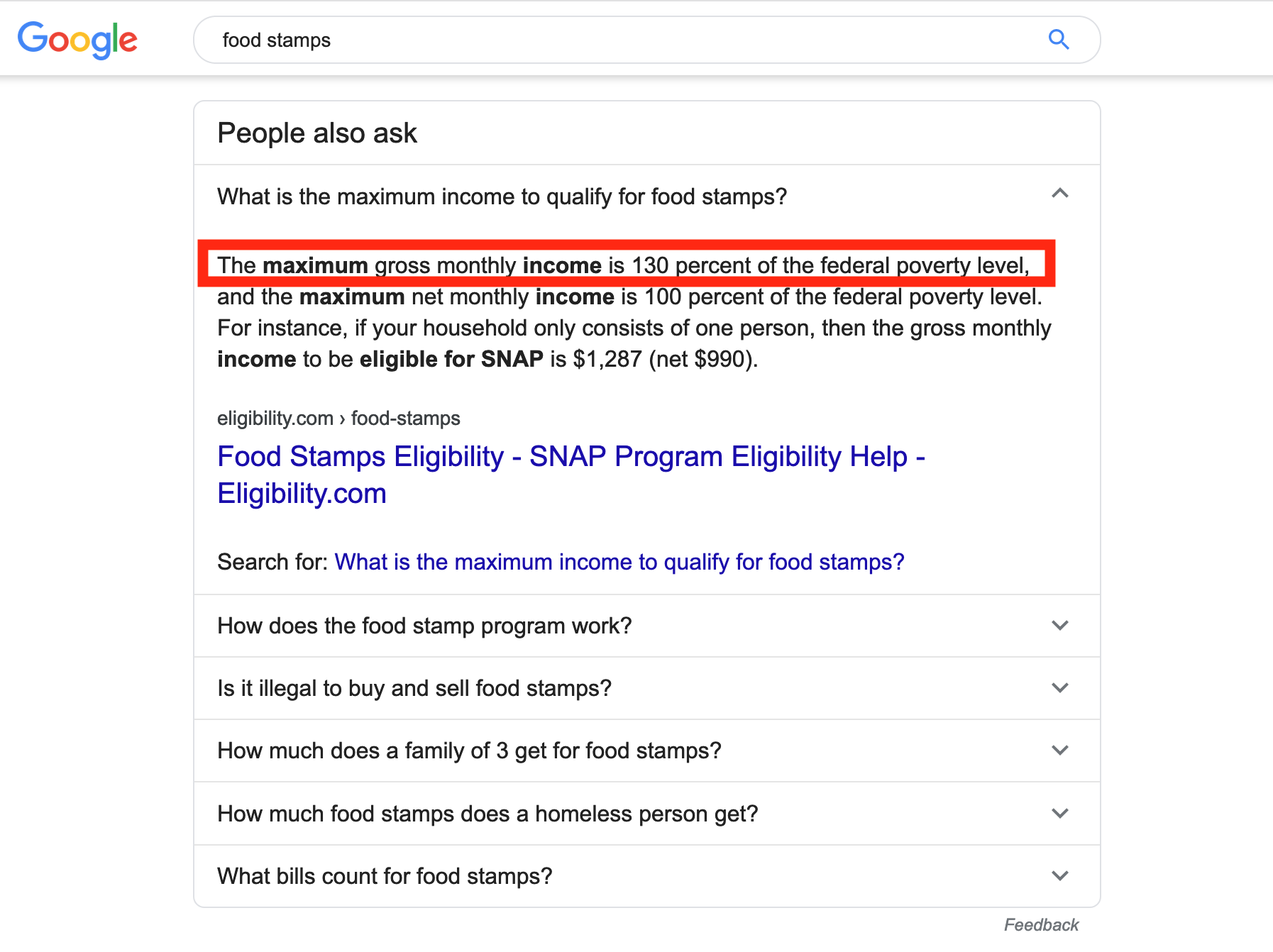
Cool! Except… in California the gross income limit is in fact 200% FPL.
So the effect of this is that someone very well may think they shouldn’t be
applying to a benefit they’re eligible for. Now that’s a bummer!
But let’s not just complain! See that little “Feedback” text in the bottom
right? We can actually tell Google what’s wrong:
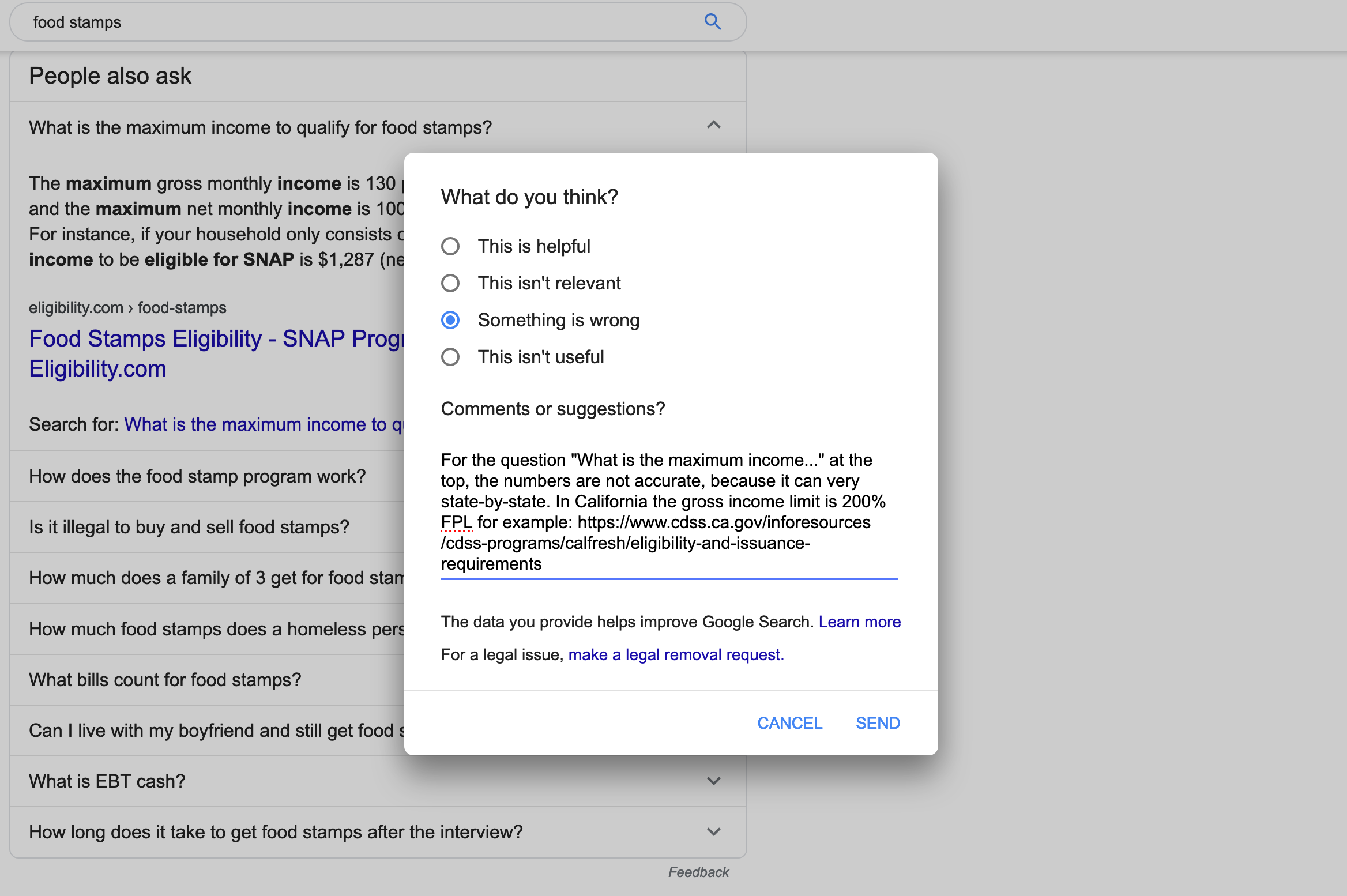
And for what it’s worth, I have seen this lead to changes in prior reports. But
we need more reports!
Now I’ve long known about problems like this, and it’s important not to look at
this as a binary: there’s a spectrum of quality problems and their impacts on
people.
This one’s not great, but it’s far less bad than, say, a scam site that
takes your info (and makes you think you’re applying for food stamps!) which
I’ve been reporting to Google about once every 6 months. (And it appears to do
something! They lose their visibility then come back with )
But what interests me most about public interest search quality is as follows:
-
Fundamentally it starts with a very tractable monitoring problem:
monitoring search results/rank/etc is a highly developed field given SEO’s
commercial value. I’m fiddling with some approaches to doing this at scale.
-
It is a huge wedge for directly accessing users: the blunt truth is that,
in general, most public interest areas don’t have awesome “official” content by
default. Lots of people are working on improving that (e.g., inside govt) but
there’s also probably a horizontal role to exist in the space for nudging
specific page quality improvements on sites that are already doing a great job
from a core content perspective, but don’t have a lot of SEO capacity, and so
may lose out right now. In some areas there may even be a space for just pure
content generation: Google keywords are, after all, a pretty decent (and highly
measurable) gauge of what people are looking for — and what content needs are
unmet. What’s most interesting is what you can do when you’re getting a lot of
users in a niche…
More to come here hopefully. Other links of note:
Advice and threads to pull here much appreciated! Send me an
email.
Legal services technology
I’ve always been interested in legal aid and legal services: it’s the final
backstop for a lot of people in very precarious circumstances for whom the
system has failed. Absent significantly-better systems, legal aid is often the
final recourse for things like appealing a disability determination or fighting an
eviction.
It also has many parallels to the public benefits world I’ve been working in the
past many years:
- A structually-underresourced system:
half the low-income Americans who
approach an LSC-funded legal aid group will receive limited or no services due
to lack of capacity)
- Administrative burdens: complex rules, overwhelming forms, legalese language
are all barriers for average people substantively accessing the justice
recourse to which they’re entitled
- An eye towards tech to deal with these: the Legal Services Corporation funds technology grants at legal aid orgs, in part (I presume) acknowledging that some types of automation/efficiency/usable DIY options are necessary if the access gap is to be closed
I was lucky enough to be able to make my way to this year’s legal
aid technology conference in January (HT
Toma) speaking on a very
practical panel doing “user experience teardowns” of legal apps (more
here).
In some ways the area seems an extreme case of the same maladies that affect
government & public interest as they relate to technology more generally.
Whereas in other domains the problems may be at a simmer, in a context where legal
aid orgs are so strapped, they’re every day turning away loads of people in need (with stats like 86% of the need unmet)
, the unacceptable nature of the status quo — and the need to push, even into uncomfortable terrain — seems much clearer.
Heck, the opening remarks even included this
line!
Of one thing I’m certain: An innovation initiative led by lawyers is an
oxymoron. Lawyers are not good at innovation. They are too
risk-averse, self-protective, prone to focusing on problems, and too wedded to
precedent to be able to drive change at scale.
Misc notes related to this:
Administrative burdens in the NY Times
Emily Badger and Margot Sanger-Katz have a very neat interactive on the New York
Times site, very explicitly (look at the URL!) informed by the great work of
Pamela Herd and Don
Moynihan on administrative burdens.
Take a look and do the quiz. It’s neat.
That said, what do I wish it did a bit differently? I believe much more in
show, don’t tell. While taking a quiz about your postal mail habits may be
useful, it’s not the same as showing the really-existing ground truth.
For example, New Hampshire Public Radio had this great
piece back in June that wasn’t abstracting it: it had screenshots (from a legal aid org!) showing how a user could not actually meet the requirements on the website.
The power of this is that, while electeds may disagree about whether work
requirements should exist in Medicaid… probably no one thinks it should be
impossible to use the web site. (For another example, in Arkansas — also
pursuing work requirements — the web site shuts down every
night.)
The “show don’t tell” rule sticks with me to this day. It’s why (many moons ago)
we did a thing called CitizenOnboard, which
still makes the rounds! It’s quite simple: showing how things are. But,
honestly, it’s surprising how often that very basic dimension goes unaccounted
for in public decisionmaking processes.
(I have a longer rant about how we need to make “experience”
legible to the
policymaking process, but that’s for another day. Moynihan and Herd’s book
Administrative
Burden has done
a lot in that translation area, but much more is needed — with all the caveats
that legibility is a fundamentally lossy filter that will never capture
everything.)
Misc things
That’s it! If this catalyzed any thoughts for you, send me a
note.
06 Aug 2019
I find I often hear two equally counterproductive arguments about technology’s role in complex social problems.
-
Tech can simply solve the problem
-
Tech isn’t the point at all, and it’s all [politics/culture change/some other “same as it’s been” problem]
These are equally counterproductive to me. That’s because they’re both equally reductive: they simplify what we know to be hard, complex, never-fully-knowable-or-controllable problems to a singular root.
Instead, I find conversations around this become much more fruitful when a different question is asked:
“Where inside the problem can inserting some technology (not present now) change the dynamics of that problem dramatically?”
Put another way: where are there points of leverage for technology?
One example: if you see as a systems constraint that “the people who design services don’t build them based on actual users’ experiences” then injecting user testing with actual video footage of people using it is something that’s “inserting tech” (user testing) — but into a problem of power, of unequal presence.
In Piven and Cloward’s classic strategy to run a mass welfare enrollment campaign detailed in “The Weight of the
Poor” they sought to get lots of eligible people to apply for benefits. Today, modern acquisition technology (Google AdWords, Facebook ads) can make finding such an eligible person cost on the order of ~$5.
That’s leverage.
I know a tech company whose user base is ~1/4 of all enrollees in one public program. That kind of aggregation was not cost-effectively possible before, maybe, the last 10 years. Aggregating people who can take action is a profound lever for change.
Using APIs that were developed and have become commodity-cheap in the last 10 years, you or I can build a call center that scales arbitrarily, and which can layer on top of existing call centers. When you can build technology layers that give all users the “hacks” that only 1 in 1,000 figure out now: that’s leverage.
Things like Glassdoor and Zillow have removed information asymmetries between individuals and orgs by using feedback loops newly available because of underlying technology shifts. [1] That’s leverage.
The policy wonk/think tank world operates by analyzing data to generate shared views of the world, and assessments of policy choices. But that data is often held inside government: and it is through administrative politics that such data gets released (or doesn’t). But technology that can generate novel data outside of government can be… big.
Intuit — towards ends I don’t like and which I think are bad for society — exploited the fact that SEO/SEM was absolutely not a part of its regulatory
agreement with the
IRS.
Technology was not a minor detail here: it was the very enabler of regulatory
avoidance.
The higher-order abstraction here is systems theory / complex adaptive systems. This short article, Donella Meadows’ “Leverage Points: Places to Intervene in a System”, is really the best primer you can read on this.
So when I hear either derision of technology as a point of leverage, or blind worship of technology as a solution “res ipsa loquitur” (speaking for itself), I really find that either vantage point is incomplete.
In the former case (“the tech doesn’t really matter”) I think there’s a defeatism that the power dynamics of the system are not changeable — I believe history shows that these can change often suddenly. In the latter case (“tech can just solve this”), it is really a severe lack of strategy.
[1] Kevin Kwok
calls this mechanism “data content loops”.
29 Jan 2017
Building GetCalFresh, we think a lot about web performance (how fast pages load on different devices). Because our user base is low-income Californians, many of whom are using low-end Android devices.
We want to make sure using GetCalFresh to apply for food assistance is the best digital experience our users have had accessing social services: respectful, easy to use, and certainly not frustrating.
One tool in our belt for measuring GCF’s web performance is Google PageSpeed Insights, a free tool from Google that analyzes a web site and checks it for common performance issues, generating both a score and a list of suggested improvements:

We have a 71 — that’s okay, not great. We should improve that. Then again, we’re trying to enroll 2.5 million more Californians in the SNAP program, which — turns out — is a lot of work. So mayyyybe it’s not the top priority to do a bunch of work to bump our PSI score.
BUT a useful thing we can do now [1] is making sure we don’t accidentally make our PSI go down with other changes we’re making.
If you read this and in your head said SOUNDS LIKE A TASK FOR CONTINUOUS INTEGRATION, we’re of like mind.
On the GetCalFresh team we’re big fans of quick feedback loops via automation. We use test-driven development (TDD) to write almost all our code, yielding about 90% test coverage. CircleCI runs this big test suite on all commits to GitHub, and also automates some parts of our deployment pipeline. We also use Hakiri to run an automated security audit on every commit.
So I thought, hrm, this is clearly something we could automate, no?
Approach
Here’s the basic approach I took to doing this:
- Set up a standalone deploy just for a PSI check
- On every commit, have CI:
- Push to that deploy
- Ask Google to run a PSI check and compare it to the PSI on master (using a deploy running master)
- Have CI fail if that commit made our PSI go down (generating alerts for us that there’s a problem)
I used Heroku for the deployment and Circle for the CI, but folks should be able to translate this approach to their own infrastructure.
Step 1: Setting up a standalone deploy for our PSI check on Heroku
First I set up a new app on Heroku just for this, which is quite easy, especially given GetCalFresh is a Rails app:
heroku create -a gcf-pagespeedinsight
# Set some env vars to make sure the deploy is clearly not production
# (demo thing is specific to our app)
heroku config:set -a gcf-pagespeedinsight RAILS_ENV=staging
heroku config:set DEMO_MODE=true -a gcf-pagespeedinsight
# Add a git remote and push our code
git remote add pagespeedinsight https://git.heroku.com/gcf-pagespeedinsight.git
git push pagespeedinsight master
Our production infrastructure runs on AWS’ GovCloud region, but for setting up instances for other uses like this one, the ease and simplicity of Heroku can’t be beat.
Step 2: Configuring CircleCI to push to that deploy
We’ve already configured CircleCI with credentials to automatically push to our demo instance (also hosted on Heroku) so it’s pretty easy to add in this deployment. Doing so makes our circle.yml file look like this:
# circle.yml
test:
pre:
- git push git@heroku.com:gcf-pagespeedinsight.git $CIRCLE_SHA1:master
override:
- RAILS_ENV=test bundle exec rspec -r rspec_junit_formatter --format RspecJunitFormatter -o $CIRCLE_TEST_REPORTS/rspec/junit.xml
deployment:
demo:
branch: master
commands:
- git push git@heroku.com:gcfdemo.git $CIRCLE_SHA1:master
The git push ... on line 3 in the test -> pre section will deploy to our Heroku instance for PSI checks before running the test suite.
Step 3: Writing some code to run a PSI check and compare the two instances
Next we’ll need some actual code to run the check and yell loudly if our PSI fell.
Google PageSpeed Insights has an API just for this. Since it’s just a plain old request/response with the score there’s plenty of ways to do this. Since our app is Ruby on Rails, I just made a quick, procedural rake task to illustrate this:
# lib/tasks/checkpsi.rake
desc "check psi"
task :checkpsi do
url_for_staging_server_with_current_commit = "https://gcf-pagespeedinsight.herokuapp.com"
# CI already auto-deploys master to our demo site, so we use it as our comparison
# You could also compare against staging or (if bold) production
url_for_server_with_current_master = "https://demo.getcalfresh.org"
# Hit the API to run a (desktop) speed check, parse the JSON, and yank out our speed
psi_score_for_this_commit = JSON.parse(HTTParty.get("https://www.googleapis.com/pagespeedonline/v2/runPagespeed?url=#{url_for_staging_server_with_current_commit}&strategy=desktop").body)["ruleGroups"]["SPEED"]["score"]
# Google lets you use the PSI API once every 5 seconds without authenticating
puts "sleeping for 6 seconds to let Google REST (get it?)"
sleep 6
# Do the same API call but for our demo instance, aka our current master branch
psi_score_for_master = JSON.parse(HTTParty.get("https://www.googleapis.com/pagespeedonline/v2/runPagespeed?url=#{url_for_server_with_current_master}&strategy=desktop").body)["ruleGroups"]["SPEED"]["score"]
puts "PSI score for master: #{psi_score_for_master}"
puts "PSI score for this commit: #{psi_score_for_this_commit}"
# Fail CI by raising if our PSI went down
if psi_score_for_this_commit < psi_score_for_master
raise "Oh noes! PageSpeed Insight score fell from #{psi_score_for_master} to #{psi_score_for_this_commit} with this commit! Please go to https://developers.google.com/speed/pagespeed/insights/?url=#{url_for_staging_server_with_current_commit} to review the problems and fix them"
end
end
I’ve tried to be really explicit and procedural here so it’s clear to anyone using any language. There’s also a CLI utility called psi that you could use.
You could also modify this to do a bunch more with what the API returns (it has a lot more detail), for example:
- Run a mobile check too (set
strategy=mobile) in the URL
- Display the different recommendations the API returns
- Use a GitHub webhook to post content back to a pull request or commit
Step 4: Adding the check into our CI pipeline
Lastly we’ve got to add this check into our CircleCI config. That’ll make our circle.yml look like this:
# circle.yml
test:
pre:
- git push git@heroku.com:gcf-pagespeedinsight.git $CIRCLE_SHA1:master
- curl https://gcf-pagespeedinsight.herokuapp.com/
- bundle exec bin/rake checkpsi
override:
- RAILS_ENV=test bundle exec rspec -r rspec_junit_formatter --format RspecJunitFormatter -o $CIRCLE_TEST_REPORTS/rspec/junit.xml
deployment:
demo:
branch: master
commands:
- git push git@heroku.com:gcfdemo.git $CIRCLE_SHA1:master
You’ll note my curl in there — I found that it was helpful to send a request to the Heroku app right after deploying to trigger the first caching and all that jazz and provide a true comparison to our demo deploy, but I didn’t dive too much into it.
SHOW ME WHAT YOU GOT
Okay! Now we’re ready to make our app worse intentionally and see what happens! I added a commit that will sleep for 5 seconds before responding to a request to the front page. THAT OUGHTTA DO IT.

Yeeeep — CI is not stoked. And on GitHub we’ll see that CI failed and go yell at whoever did that thing.
(Aside: This is a joke. Having a psychologically safe, just culture where we understand the context of someone’s mistake which gave them the false confidence in their approach — and then you make a change in that context, like automating your test runner! — is how you actually fix problems like this.)
That’s it! Go home!
So yeah, that’s it! It was fun exploring this, and I was actually pretty surprised that no one had written this up (though many of the pieces are out there, nothing put together) so figured I’d throw it into the world and hope it’s helpful for others.
The big improvement I’d make here given more time is actually at the internal user experience level: having CI fail when the score falls is okay, but a more actionable approach towards automated feedback here would be having a GitHub webhook that commented on a pull request with a PSI score drop and diff’d the problems returned in the API so show just the thing that changed that made it fall. Then whoever’s working on that knows immediately what they changed.
Also, Google PageSpeed Insights is not The One True Metric™! So failing CI is maybe a bit too aggressive, since there could certainly be contexts where a falling PSI score is a fair tradeoff.
But the bottom line is if you automate your feedback loops, you are more effective at responding to them. Hope this helps some folks do that.
Oh, and if this kind of development philosophy appeals to you, we are hiring engineers and other roles for both the GetCalFresh project and other excellent ones at Code for America.
[1] …especially given that I’m writing this on a weekend and this is more fun exploration than an exercise in strict prioritization…
05 Jun 2014
Sometimes, when you’re early in programming in a new language, darkness washes over you — you’ve written 70% of the code to do some thing, but then you don’t know the syntax to do that next step.
In these cases, it’s great to use a breakpoint — a line of code that stops your code there, and lets to interactively type lines with the full context of the code above, but with immediate feedback (this interactive prompt is called a “REPL”).
You’ve probably used a REPL before — it’s what happens when you go to a terminal and type irb (Ruby), python, or node without any arguments. In a REPL, you type code, and immediate see what that code returns.
By adding breakpoints, we can enter that almost zen-like immediate feedback loop at any point we want in our code.
Because I love using interactive breakpoints to debug, and often find myself working across languages, here’s a quick guide on using them across Python, Ruby, and Javascript (Node).
Python: IPython embed
In Python, we can use a breakpoint with IPython’s embed function.
First, make sure you have IPython installed:
pip install ipython
Then we can add a breakpoint by importing embed, and using the embed() function:
from IPython import embed
# Misc code
embed()
Ruby: Pry
In Ruby, we can add a breakpoint with the nifty pry gem.
First, make sure you have pry installed:
gem install pry
Now, require pry in your code, and drop in using binding.pry:
require 'pry'
# Misc code
binding.pry
Node.js: Debugger
In Node.js, we can add a breakpoint with the debug feature of Node.js and adding a debugger line.
The process is slightly trickier than for Ruby or Python, buuut we don’t have to install anything this time!
Let’s walk through how to use debugger. In our Javascript, we add debugger to create a breakpoint. So say we have simple file called hello.js with the following:
var x = 'hello';
debugger;
We can go to that breakpoint by first running the file with debug added in, i.e. node debug hello.js:
$~: node debug hello.js
< debugger listening on port 5858
connecting... ok
break in hello.js:1
1 var x = 'hello';
2 debugger;
3
debug >
Now, at the debug prompt, we do two things:
- Type
c and hit enter
- Type
repl and hit enter
debug> c
break in hello.js:2
1 var x = 'hello';
2 debugger;
3
4 });
debug> repl
Press Ctrl + C to leave debug repl
>
Congrats! Now you’re at an interactive prompt at the breakpoint.
An example: learning how to deal with GeoJSON in Python
Let’s say you’re exploring the wild and crazy world of open geo, and you’re super stoked to play around with GeoJSON — a JSON data format for storing geographic data — and you want to do it in Python.
You’re given a GeoJSON file with a list of bars in Oakland where you might get to hear the Descendents, and you want write a Python script to print out the name of each.
Since you’re new to this whole geo game, you don’t really know how GeoJSON nests its attributes, and want to be able to play with the JSON data as a Python dictionary to figure that out.
So you’ve written a script that loads the GeoJSON and turns it into a dictionary. (You can get this script and data from GitHub with git clone https://gist.github.com/9a6fc83d1a67939c5110.git)
from IPython import embed
import json
geodata_json_string = open('good_oakland_bars.geojson').read()
geodata_dict = json.loads(geodata_json_string)
embed()
Now, when we run python py_interactive_breakpoint.py, we’ll be dropped to an interactive breakpoint to play around with the geodata_dict variable.
By playing around in the REPL — most simply by typing geodata_dict and seeing what it looks like — we figure out that geodata_dict['features'] is an array of the bars, and that GeoJSON stores the non-geographic attributes in a properties dictionary.
So we realize we can access the name of the first bar by doing geodata_dict['features'][0]['properties']['name'] and this opens the door to a nifty for loop to print out those names.
We can even write try writing that for loop in the REPL first, and if it works, we can then migrate it over to our file.
Ta-da! REPL-driven-development, yo.
Parting thought
When coding, always remember the words of The Stranger — sometimes you eat the bar, and sometimes the bar, well, it eats you.
So when you feel like the bar’s eating you, try using a breakpoint.
And if that doesn’t help, you can always say “fuck it” and write a Lebowski-themed blog post.
If you found this helpful, spotted a problem, or have additional thoughts, I’d love to hear from you at @allafarce or by e-mail.
17 Mar 2014
Now a few months out the intense tunnel of my Code for America fellowship year, I’ve had a bit more time and mental space to sip coffee by Lake Merritt and reflect on issues of technology and government.
The “experience problem”
A mantra oft-repeated at CfA is that we’re “building interfaces to government that are simple, beautiful, and easy to use.”
And that should be a core concern: bringing human-centered design and user experience thinking to the interfaces that government presents is important work. Governments all too often tend to privilege legal accuracy over creating an accessible, enjoyable experience for its constituents.
But this “experience problem” is really only one piece of the civic tech puzzle.
Data integration: a whole other can of worms
Many of the problems government confronts with technology are fundamentally about data integration: taking the disparate data sets living in a variety of locations and formats (SQL Server databases, exports from ancient ERP systems, Excel speadsheets on people’s desktops) and getting them into a place and shape where they’re actually usable.
Among backend engineers, these are generically referred to as ETL problems, or extract-transform-load operations. The notion is that integrating data involves three distinct steps:
-
Extract: getting data out of some system where it is stored, and where updates are made
-
Transform: reformatting and reshaping the data in ways that make it usable
-
Load: putting the transformed data into another system, generally something where analyzing it or combining it with other data is easy for end-users
Let’s look at an example:
The Mayor’s staff wants to put a simple dashboard on the City web site with building permits data. They’d like a map and some simple counts to provide a lens on local economic development to residents.
-
Building permits are put into software procured in 2002 called PermitManager. IT staff write a script that nightly runs permit_manager_export.exe, which dumps the data (permits.csv) to a shared drive. (extract)
-
The permit data system only contains addresses in raw text, but to map it it needs latitude and longitudes. The GIS team writes a script that every morning takes permits.csv and adds latitude and longitude columns based on the address text. (transform)
-
The City has an open data portal that can generate a web map for any data set on it containing latitude and longitude. Staff write a script that uploads permits-with-latitude-and-longitude.csv to the open data portal every afternoon, and embed the auto-generated web map into the city’s web site. (load)
I’ve explained ETL in the above way plenty of times, and the thing is, almost everyone I talk to finds it easy to understand. They just hadn’t thought about it too much.
And one of the foibles here is that many government staff – particularly those at the high level – lack the basic technical language to be able to understand the structure of the ETL problem and find and evaluate the resources out there.
The fact that I can go months hearing about “open data” without a single mention of ETL is a problem. ETL is the pipes of your house: it’s how you open data.
ETL: a hard ^#&@ing problem
Did you notice in the above example that I have three mentions of city staff writing scripts? Wasn’t that weird? Why didn’t they use some software that automatically does this? If you Google around about ETL, perhaps the most common question is whether one should use some existing ETL software/framework or just write one’s own ETL code from scratch.
This is at the core of the ETL issue: because the very problem of data integration is about bringing together disparate, heterogeneous systems, there isn’t really a clear-winner, “out-of-the-box” solution.
Couple with the fact that governments seem to have an almost vampiric thirst for clearly market-dominating, “enterprise” solutions – c.f., the old adage that “no one ever got fired for hiring IBM” – and you find yourself confronting a scary truth.
What’s more, ETL is actually just an intrinsically hard technical problem. Palantir, a company which is very good with data, essentially solves the problem by throwing engineers at it. They have a fantastic analytic infrastructure at their core, and they pay large sums of money to very smart people to do one thing: write scripts to get clients’ data into that infrastructure.
What is to be done?
First a note on what not to do: do not try to buy your way out of this. There is no single solution, no single piece of software you can buy for this. Anyone who tells you otherwise is is being disingenuous. And if you pay someone external to integrate 100% your data right now, you will be paying them in 11 days when you change one tiny part of your system. And I bet it will be at a mark-up.
Here are a few paths forward I see as promising:
- Build internal capacity: Hire smart, intellectually curious people who learn what they need to know to solve a problem. In fact, don’t even start by hiring. Many of these people probably already work with you, but are hobbled by the inability to, say, install new software on their desktop, or by cultural norms that make trying out new things unacceptable.
Because data integration is a hard problem with new challenges each time you approach it, the best way to tackle them is to have motivated people who love to solve new problems, and give them the tools they need (whether that’s training, software, or a supervisorial mandate.) To borrow and modify a phrase: let them run Linux.
As Andrew Clay Shafer has said: if you’re not building a learning organization, you’re losing to one. And I can tell you, governments are, for the most part, not building learning organizations at the moment.
- Explore the resources out there: I’ve started putting together a list of ETL resources for government. I’d love contributions. With just the knowledge of the acronym “ETL” and the basics of what it means you can start to think about how you can solve your own data problems with smaller tools (Windows Job Scheduler is analogous to In-N-Out’s secret sauce.)
Because it’s a generic (not just government) problem, there’s also plenty of other resources out there. The data journalism folks have done a great job of writing tutorials that make existing tools accessible, and we need to follow suit (and work with them.)
- Collaborate for God’s sake!: EVERY organization dealing with data is dealing with these problems. And governments need to work together on this. This is where open source presents invaluable process lessons for government: working collaboratively, and in the open, can float all boats much higher than they currently are.
Whether it’s putting your scripts on GitHub, asking and answering questions on the Open Data StackExchange, or helping out others on the Socrata support forums, collaboration is a key lever for this government technology problem.
Wanted: government data plumbers
In a forthcoming post, I hope to document some of the concrete experiences and lessons I’ve had in doing data plumbing in government, most recently some of the exciting experiments we’re running in Oakland, California.
But I’m also writing this blog post – perhaps a bit audaciously – as a call to arms: all of us doing data work inside government need to start writing more publicly about our processes, hacks, and tools, and collaborating across boundaries.
From pure policy wonks who know just enough VBA to get stuff done to the Unix geeks whose awk knowledge strikes fear into the hearts of most sysadmins, we need to communicate more, and more publicly.
I’ve coded for America. It was hard, hard work, but incredibly fulfilling. So to my fellow plumbers I say: let’s ETL for America.
If these ramblings piqued your interest, I’d love to hear from you at @allafarce or by e-mail.